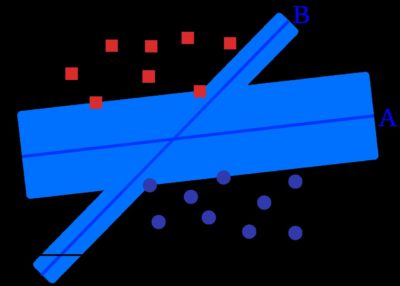
Mit Abständen und Linien arbeiten auch Support Vector Machines (SVMs). Bereits in den 1930er- und 1950er-Jahren gab es Gedanken zu diesem Algorithmus, aber erst in den 1990ern gelang den Support Vector Machines der Durchbruch. Bei den SVMs geht es häufig um eine Klassifikation: Datenpunkte sollen voneinander in verschiedene Klassen getrennt werden. Wie bei der linearen Regression legt man dazu eine Linie zwischen die Datenpunkte. Allerdings arbeitet man nun nicht allein mit dieser Linie, sondern mit zwei Hilfslinien, den Support-Vektoren, die man parallel zur ersten Linie setzt. Nun gilt es, die Hauptlinie so zu positionieren, dass die Hilfslinien möglichst weit entfernt von ihr verlaufen, ohne dass Datenpunkte die Hilfslinien überschreiten.
Nicht immer kann man die Hilfslinien so setzen, dass alle Datenpunkte außerhalb liegen. In diesem Fall berechnet man für jeden hereinragenden Datenpunkt einen Fehler (basierend auf dem Abstand zur Hilfslinie), bildet die Summe der Fehler und sucht dann nach der Position der Linie, die den geringsten Fehler aufweist. Das Besondere an Support Vector Machines: Man kann Dimensionen hinzufügen, um die Daten besser zu trennen – der sogenannte Kernel Trick.